TLA+ Wiki intro
Welcome to TLA+ wiki. This wiki was created in response to the 2024 TLA+ community survey. More specifically, it aims to address the following feedbacks:
- Difficulty Understanding Existing Codebase and Documentation: Respondents note challenges in comprehending the existing codebase and documentation. The lack of clear structure and architecture documentation, as well as the complexity of the Java codebase, pose significant obstacles for newcomers.
- Navigation and Documentation: Navigating the various TLA+ resources and finding relevant documentation is identified as a challenge. Respondents note scattered and sometimes non-existent documentation, making it difficult to find the most relevant resources and assistance.
- Documentation and Tooling: There is a strong consensus on the need for improved documentation, particularly in the form of better organised and comprehensive resources. This includes better documentation for the entire project, better release cycles for all TLA+ tools, and centralised documentation on a website rather than PDFs.
The takeaway also sums up the mission of this wiki well:
Streamlining Documentation: There's a clear demand for better-organised documentation and centralised resources with a more modern interface to cater to users' preferences for accessible and comprehensive guidance.
This is a community-backed effort, so if you find errors or suggestions/ideas/feedback, please create a PR or an issue.
If you want to contribute, please check Contributing page with detailed step by step. The source of this website is hosted here.
Contributing
Contribution to the tla-wiki are very welcome! To contribute to this book, you will need a Github Account.
The best path to contribute to this wiki is to: 0. Check if anyone is already working on your same idea by checking issues.
- Create an issue stating what page/contribution/fix you would like to contribute to, or find an unassigned issue you'd like to work on.
- You can:
If you don't have a github account but still you'd like to contribute, please send the diffs via email to me. You can find my email at the bottom of my page here.
Learning TLA+ and Model Checking
-
Specyfing systems: by Leslie Lamport is still the reference book for TLA+ and its tools
-
The Specification Language TLA+: Another good manuscript by Stephan Merz explaining TLA+ specification language: Sect. 2 introduces TLA+ by way of a first specification of the resource allocator and illustrates the use of the tlc model checker. The logic TLA is formally defined in Sect. 3, followed by an overview of TLA+ proof rules for system verification in Sect. 4. Section 5 describes the version of set theory that underlies TLA+, including some of the constructions most frequently used for specifying data. The resource allocator example is taken up again in Sect. 6, where an improved high-level specification is given and a step towards a distributed refinement is made. Finally,Sect. 7 contains some concluding remarks
Resources
A collection of resources about TLA+ can be found on the awesome-tla+ repository. Feel free to contribute with your useful links.
Learning Pluscal
PlusCal is an algorithm language—a language for writing and debugging algorithms. It is especially good for algorithms to be implemented with multi-threaded code. Instead of being compiled into code, a PlusCal algorithm is translated into a TLA+ specification. An algorithm written in PlusCal is debugged using the TLA+ tools—mainly the TLC model checker. Correctness of the algorithm can also be proved with the TLAPS proof system, but that requires a lot of hard work and is seldom done.
The easiest way to learn pluscal, is to read the Pluscal tutorial by Lamport. Free, and readable online; it can be found here: https://lamport.azurewebsites.net/tla/tutorial/contents.html
Pluscal comes into two flavors: C-Style and P-Style. For a more complete overview of Pluscal, there is a manual available for each style: c-manual.pdf, p-style.pdf.
To have a taste of each style:
P-Syntax
---- MODULE Playground ----
EXTENDS TLC, Naturals
(*--algorithm Playground
variable x = 0, y = 0;
begin
while x > 0 do
if y > 0 then y := y-1;
x := x-1
else x := x-2
end if
end while;
print y;
end algorithm;
*)
====
C-Syntax style
---- MODULE Playground ----
EXTENDS TLC, Naturals
(*--algorithm Playground {
variables x = 0, y = 0; {
while (x > 0) {
if (y > 0) {
y := y-1;
x := x-1;
} else x := x-2
};
print y;
}
}*)
====
TLA+ Vs xxx
This page describes how does TLA+ compare to over specification and model checking tools.
Summary
You can access to a quick pdf summary about the tla+ language here: https://lamport.azurewebsites.net/tla/summary-standalone.pdf.
This is a web accessible version.
Summary of TLA
- Module-Level Constructs
- The Constant Operators
- Miscellaneous Constructs
- Action Operators
- Temporal Operators
- User-Definable Operator Symbols
- Precedence Ranges of Operators
- Operators Defined in Standard Modules.
- ASCII Representation of Typeset Symbols 1
Module-Level Constructs
MODULE Begins the module or submodule named .
EXTENDS
Incorporates the declarations, definitions, assumptions, and theorems from the modules named into the current module.
CONSTANTS
Declares the to be constant parameters (rigid variables). Each is either an identifier or has the form , the latter form indicating that is an operator with the indicated number of arguments.
\text { VARIABLES } x_{1}, \ldots, x_{n}^{(1)}
Declares the to be variables (parameters that are flexible variables).
ASSUME
Asserts as an assumption.
Defines to be the operator such that equals exp with each identifier replaced by . (For , it is written .)
Defines to be the function with domain such that for all in . (The symbol may occur in exp, allowing a recursive definition.)
(1) The terminal S in the keyword is optional.
(2) may be replaced by a comma-separated list of items , where is either a comma-separated list or a tuple of identifiers.
INSTANCE WITH
For each defined operator of module , this defines to be the operator whose definition is obtained from the definition of in by replacing each declared constant or variable of with . (If , the WITH is omitted.) INSTANCE WITH
For each defined operator of module , this defines to be the operator whose definition is obtained from the definition of by replacing each declared constant or variable of with , and then replacing each identifier with . (If , the WITH is omitted.)
THEOREM
Asserts that can be proved from the definitions and assumptions of the current module.
LOCAL def
Makes the definition(s) of def (which may be a definition or an INSTANCE statement) local to the current module, thereby not obtained when extending or instantiating the module.
Ends the current module or submodule.
The Constant Operators

Sets
.
[Set consisting of elements
(2) [Set of elements in satisfying ]
[Set of elements such that in
SUBSET [Set of subsets of ]
UNION Union of all elements of
Functions
\begin{array}{ll} f[e] & {[\text { Function application] }} \ \text { DOMAIN } f & {[\text { Domain of function } f]} \ {[x \in S \mapsto e]{ }^{(1)}} & {[\text { Function } f \text { such that } f[x]=e \text { for } x \in S]} \ {[S \rightarrow T]} & {[\text { Set of functions } f \text { with } f[x] \in T \text { for } x \in} \ {\left[f \text { EXCEPT }!\left[e_{1}\right]=e_{2}\right]^{(3)}} & {\left[\text { Function } \widehat{f} \text { equal to } f \text { except } \widehat{f}\left[e_{1}\right]=e_{2}\right]} \end{array}
Records
Tuples
\begin{array}{ll} e[i] & {\left[\text { The } i^{\text {th }} \text { component of tuple } e\right]} \ \left\langle e_{1}, \ldots, e_{n}\right\rangle & {\left[\text { The } n \text {-tuple whose } i^{\text {th }} \text { component is } e_{i}\right]} \ S_{1} \times \ldots \times S_{n} & \text { [The set of all } \left.n \text {-tuples with } i^{\text {th }} \text { component in } S_{i}\right] \end{array}
(1) may be replaced by a comma-separated list of items , where is either a comma-separated list or a tuple of identifiers
(2) may be an identifier or tuple of identifiers.
(3)! or !.h may be replaced by a comma separated list of items , where each is or..
Miscellaneous Constructs

Action Operators
| The value of in the final state of a step] | |
|---|---|
| ENABLED | An step is possible |
| UNCHANGED | |
| Composition of actions |
Temporal Operators
\begin{array}{ll} \square F & {[F \text { is always true }]} \ \diamond F & {[F \text { is eventually true }]} \ \mathrm{WF}{e}(A) & {[\text { Weak fairness for action } A]} \ \mathrm{SF}{e}(A) & {[\text { Strong fairness for action } A]} \ F \sim G & {[F \text { leads to } G]} \end{array}
User-Definable Operator Symbols
Infix Operators
| ++ | ||||||
|---|---|---|---|---|---|---|
| - | ||||||
| -- | ||||||
| (1) | ||||||
Postfix Operators (7)
-
(1) Defined by the Naturals, Integers, and Reals modules.
(2) Defined by the Reals module.
(3) Defined by the Sequences module.
(4) is printed as .
(5) Defined by the Bags module.
(6) Defined by the module.
(7) is printed as , and similarly for and .
Precedence Ranges of Operators
The relative precedence of two operators is unspecified if their ranges overlap. Left-associative operators are indicated by (a).

Operators Defined in Standard Modules.
Modules Naturals, Integers, Reals
\begin{aligned} & +\quad-{ }^{(1)} \quad * \quad /^{(2)} \quad \sim^{-(3)} \quad \text {.. } \quad \text { Nat } \quad \text { Real }^{(2)} \ & \div \quad % \quad \geq \quad>\quad \text { Int }^{(4)} \quad \text { Infinity }{ }^{(2} \end{aligned}
(1) Only infix - is defined in Naturals.
(2) Defined only in Reals module.
(3) Exponentiation.
(4) Not defined in Naturals module.
Module Sequences
| Head | SelectSeq | SubSeq | |
|---|---|---|---|
| Append | Len | Seq | Tail |
Module FiniteSets
IsFiniteSet Cardinality
Module Bags
| BagIn | CopiesIn | SubBag | |
|---|---|---|---|
| BagOfAll | EmptyBag | ||
| BagToSet | IsABag | ||
| BagCardinality | BagUnion | SetToBag |
Module RealTime
RTBound RTnow now (declared to be a variable)
Module
Print Assert JavaTime Permutations SortSeq
ASCII Representation of Typeset Symbols
| or | land | V | or lor | ||
|---|---|---|---|---|---|
| or | not or \neg | or \equiv | |||
| \in | \notin | or | |||
| \rangle | [] | ||||
| \leq or | or | \geq or >= | |||
| \ll | |||||
| \prec | \succ | ||||
| \preceq | \succeq | \div | |||
| \subsete | \supseteq | . | \cdot | ||
| \subset | \supset | 0 | \o or \circ | ||
| \sqsubse | \sqsupset | \bullet | |||
| \sqsubse | eteq | \sqsupseteq | \star | ||
| -1 | O | \bigcirc | |||
| \sim | |||||
| \simeq | |||||
| \cap or | \intersect | \cup or \union | \asymp | ||
| \sqcap | \sqcup | \approx | |||
| or 1 | \oplus | \uplus | \cong | ||
| or 1 | \ominus | or \times | \doteq | ||
| (.) or 1 | \odot | 2 | |||
| or | \otimes | \propto | |||
| (/) or 1 | \oslash | "s" | "s" (1) | ||
| , | |||||
| ]_v | \rangle | ||||
| SF_v |
(1) is a sequence of characters.
(2) and are any expressions.
(3) a sequence of four or more - or characters.
(1) Action composition (\cdot).
(2) Record field (period).
Config files
The config files are used for TLC model checking.
The possible contents of the config file itself are presented below. The config file has .cfg extension, and usually has the same name of your spec (.tla file).
TODO: values supported in config files. Typed model values.
Table Of Contents:
Supported Sections
Constants or Constant (they're aliases)
You can use it to specify the constant used in the model.
CONSTANTS
Processes = {1,2,3}
Equivalent to:
CONSTANT
Processes = {1,2,3}
SPECIFICATION
The name of the predicate that usually has the form of: Init /\ [][Next]_vars /\backslash.
Usually per convention it's called Spec.
SPECIFICATION
Spec
INVARIANT or INVARIANTS (they're aliases)
Invariants that you want to verify.
INVARIANT
TypeOk \* Always verify your types!
PROPERTIES or PROPERTY (they're aliases)
Temporal properties you want to verify.
PROPERTIES
Termination
CONSTRAINT or CONSTRAINTS (they're aliases)
Used to restrict the state space to be explored. Helps restricting unbounded models.
SYMMETRY
Helps reducing the state space to explore by removing symmetric states. You can't check liveness properties when symmetry is used. See: https://federicoponzi.github.io/tlaplus-wiki/codebase/wishlist.html#liveness-checking-under-symmetry-difficulty-high-skills-java-tla
VIEW
CHECK_DEADLOCK
POSTCONDITION
ALIAS
INIT
NEXT
A copy-pastable example:
\* Add statements after this line.
CONSTANTS
SPECIFICATION
Spec
INVARIANT
TypeOK
PROPERTIES
\* Termination
\* Check presence of deadlocks. It's true by default.
CHECK_DEADLOCK
FALSE
Resources
Check the EBNF and more info on the apalache documentation here.
FAQ
Table Of Contents:
- Do you need to know math to learn TLA+?
- Can I use TLA+ for web development?
- Do you get trace for violated temporal properties?
Do you need to know math to learn TLA+?
Can I use TLA+ for web development?
Do you get trace for violated temporal properties?
No, state trace for violated temporal properties is currently not supported.
Distributed mode and Cloud mode
When we need to model check a model that has a large state space, we can run tlc in distributed mode. In this mode, TLC will run in multiple machines. Cloud mode is distributed mode, but automatically spawns up instances in the supported clouds.
There have been no reported issues, and nothing is fundamentally broken with either Distributed TLC or Cloud TLC. However, we no longer have sponsored access to AWS to run Cloud TLC as part of our CI testing. Additionally, cloud providers often change their APIs, and the jclouds library [1] that Cloud TLC depends on has not been updated in a while. The dropdown menu for selecting the cloud has been moved in the Toolbox’s nightly build (see attached screenshot).
Distributed TLC can be used from the command line [2], but there is no support in the VSCode extension.
We've found that TLC’s simulation mode is very effective at finding counterexamples. For instance, simulation mode found a variant of a counterexample in about 10 minutes, which took model checking two days to find. I recommend running TLC in simulation mode on a multi-core machine for an extended period before attempting large-scale exhaustive model checking on a single machine or using distributed model checking.
- [1] https://jclouds.apache.org https://jclouds.apache.org/ and https://github.com/lemmy/jclouds2p2
- [2] https://tla.msr-inria.inria.fr/tlatoolbox/doc/model/distributed-mode.html
Limitations
In distributed mode TLC cannot check liveness properties, nor check random or depth-first behaviours.
Distributed TLC does not support TLCGet/TLCSet operator. It would require synchronization among all (distributed) workers. In distributed mode, it is of limited use anyway.
Using TLA+
Visual Studio Code Extension
This is the fastest and easiest way to get started with TLA+ and TLC.
- Download visual studio
- Search for the tla+ plugin in the extensions tab.
- Make sure to install TLA+ Nightly. It is usually stable, it has more features and extension release is lagging behind.
Additionally, you might want to enable automatic module parsing on saves: https://github.com/tlaplus/vscode-tlaplus/wiki/Automatic-Module-Parsing
Resources
The plugin source code can be found on github: https://github.com/tlaplus/vscode-tlaplus
TLA+ Toolbox
The TLA+ Toolbox is an IDE for TLA+.
TLC Model Checker
TLC is an explicit state model checker originally written by Yu et al. [1999] to verify TLA+ specifications. TLC can check a subset of TLA+ that is commonly needed to describe real-world systems, most notably finite systems.
To run it, you will need Java runtime environment version 11.
Table Of Contents:
- Getting the latest stable release
- Building TLC from sources
- Running the tla2tools.jar
- CLI Parameters
- Undocumented flags
- Good to know:
Getting the latest stable release
You can always download the latest stable release from the release page on github: https://github.com/tlaplus/tlaplus/releases/
Building TLC from sources
You will need JDK 11 and ant.
- Download the repository from github: https://github.com/tlaplus/tlaplus
- Go to tlaplus/tlatools/org.lamport.tlatools and run:
ant -f customBuild.xml compile dist
You can then find the jar file inside tlaplus/tlatools/org.lamport.tlatools/dist/tla2tools.jar
Running the tla2tools.jar
To run the TLC model checker:
java -jar ./dist/tla2tools.jar <MySpec.tla>
the cli will automatically use the config file called MySpec.cfg in that same directory, if present.
JVM options
See https://docs.oracle.com/en/java/javase/20/gctuning/available-collectors.html#GUID-F215A508-9E58-40B4-90A5-74E29BF3BD3C
If (a) peak application performance is the first priority and (b) there are no pause-time requirements or pauses of one second or longer are acceptable, then let the VM select the collector or select the parallel collector with -XX:+UseParallelGC.
Simulation, nor Model Checking seem to work well with G1GC, but Trace Validation does not for some reason, and is much slower unless -XX:+UseParallelGC is used.
In all cases, pauses don't matter, only throughput does.
java -XX:+UseParallelGC
CLI Parameters
You can always access the latest information by using
java -jar ./dist/tla2tools.jar -help
Not all options are exposed through it though. These are the options that are supported but missing from the -help:
-lncheck: Check liveness properties at different times of model checking. Supported values are "default", "final", "seqfinal". "default" will check liveness at every step, while final will search it only at the end of the exploration. "seqfinal" is anlias for "final". -lncheck final option postpones the search of Strongly Connected Components in the behavior graph until after the safety check has been completed
These are all the options outputted from the cli at the time of writing from master:
-aril num
adjust the seed for random simulation; defaults to 0
-checkpoint minutes
interval between check point; defaults to 30
-cleanup
clean up the states directory
-config file
provide the configuration file; defaults to SPEC.cfg
-continue
continue running even when an invariant is violated; default
behavior is to halt on first violation
-coverage minutes
interval between the collection of coverage information;
if not specified, no coverage will be collected
-deadlock
if specified DO NOT CHECK FOR DEADLOCK. Setting the flag is
the same as setting CHECK_DEADLOCK to FALSE in config
file. When -deadlock is specified, config entry is
ignored; default behavior is to check for deadlocks
-debug
print various debugging information - not for production use
-debugger nosuspend
run simulation or model-checking in debug mode such that TLC's
state-space exploration can be temporarily halted and variables
be inspected. The only debug front-end so far is the TLA+
VSCode extension, which has to be downloaded and configured
separately, though other front-ends could be implemeted via the
debug-adapter-protocol.
Specifying the optional parameter 'nosuspend' causes
TLC to start state-space exploration without waiting for a
debugger front-end to connect. Without 'nosuspend', TLC
suspends state-space exploration before the first ASSUME is
evaluated (but after constants are processed). With 'nohalt',
TLC does not halt state-space exploration when an evaluation
or runtime error is caught. Without 'nohalt', evaluation or
runtime errors can be inspected in the debugger before TLC
terminates. The optional parameter 'port=1274' makes the
debugger listen on port 1274 instead of on the standard
port 4712, and 'port=0' lets the debugger choose a port.
Multiple optional parameters must be comma-separated.
Specifying '-debugger' implies '-workers 1'.
-depth num
specifies the depth of random simulation; defaults to 100
-dfid num
run the model check in depth-first iterative deepening
starting with an initial depth of 'num'
-difftrace
show only the differences between successive states when
printing trace information; defaults to printing
full state descriptions
-dump file
dump all states into the specified file; this parameter takes
optional parameters for dot graph generation. Specifying
'dot' allows further options, comma delimited, of zero
or more of 'actionlabels', 'colorize', 'snapshot' to be
specified before the '.dot'-suffixed filename
-dumpTrace format file
in case of a property violation, formats the TLA+ error trace
as the given format and dumps the output to the specified
file. The file is relative to the same directory as the
main spec. At the time of writing, TLC supports the "tla"
and the "json" formats. To dump to multiple formats, the
-dumpTrace parameter may appear multiple times.
The git commits 1eb815620 and 386eaa19f show that adding new
formats is easy.
-fp N
use the Nth irreducible polynomial from the list stored
in the class FP64
-fpbits num
the number of MSB used by MultiFPSet to create nested
FPSets; defaults to 1
-fpmem num
a value in (0.0,1.0) representing the ratio of total
physical memory to devote to storing the fingerprints
of found states; defaults to 0.25
-gzip
control if gzip is applied to value input/output streams;
defaults to 'off'
-h
display these help instructions
-maxSetSize num
the size of the largest set which TLC will enumerate; defaults
to 1000000 (10^6)
-metadir path
specify the directory in which to store metadata; defaults to
SPEC-directory/states if not specified
-noGenerateSpecTE
Whether to skip generating a trace exploration (TE) spec in
the event of TLC finding a state or behavior that does
not satisfy the invariants; TLC's default behavior is to
generate this spec.
-nowarning
disable all warnings; defaults to reporting warnings
-postCondition mod!oper
evaluate the given (constant-level) operator oper in the TLA+
module mod at the end of model-checking.
-recover id
recover from the checkpoint with the specified id
-seed num
provide the seed for random simulation; defaults to a
random long pulled from a pseudo-RNG
-simulate
run in simulation mode; optional parameters may be specified
comma delimited: 'num=X' where X is the maximum number of
total traces to generate and/or 'file=Y' where Y is the
absolute-pathed prefix for trace file modules to be written
by the simulation workers; for example Y='/a/b/c/tr' would
produce, e.g, '/a/b/c/tr_1_15'
-teSpecOutDir some-dir-name
Directory to which to output the TE spec if TLC generates
an error trace. Can be a relative (to root spec dir)
or absolute path. By default the TE spec is output
to the same directory as the main spec.
-terse
do not expand values in Print statements; defaults to
expanding values
-tool
run in 'tool' mode, surrounding output with message codes;
if '-generateSpecTE' is specified, this is enabled
automatically
-userFile file
an absolute path to a file in which to log user output (for
example, that which is produced by Print)
-view
apply VIEW (if provided) when printing out states
-workers num
the number of TLC worker threads; defaults to 1. Use 'auto'
to automatically select the number of threads based on the
number of available cores.
Undocumented flags
Some flags can be set passing java parameters to tlc, they are mostly undocumented (for now) and can be found by searching for "Boolean.getBoolean" in the codebase.
Good to know:
When using the '-generateSpecTE' you can version the generated specification by doing:
./tla2tools.jar -generateSpecTE MySpec.tla && NAME="SpecTE-<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord">+</span></span></span></span>NAME/g" SpecTE.tla > $NAME.tla
If, while checking a SpecTE created via '-generateSpecTE', you get an error message concerning CONSTANT declaration and you've previous used 'integers' as model values, rename your model values to start with a non-numeral and rerun the model check to generate a new SpecTE.
If, while checking a SpecTE created via '-generateSpecTE', you get a warning concerning duplicate operator definitions, this is likely due to the 'monolith' specification creation. Try re-running TLC adding the 'nomonolith' option to the '-generateSpecTE' parameter.
When using more than one worker, the reported depth might differ across runs. For small models, use a single worker. For large models, the diameter will almost always appear deterministic.
TLC Model Checker: How TLC works
This is a concise overview of how TLC model checker works, taken from Markus Kuppe's master thesis: https://lemmster.de/talks/MSc_MarkusAKuppe_1497363471.pdf (section 2.2.3)
TLC is an explicit state model checker originally written by Yu et al. [1999] to verify TLA+ specifications. TLC can check a subset of TLA+ that is commonly needed to describe real-world systems, most notably finite systems.
The schematic figure 2.2.3 is a simplified view on TLC. A user of TLC, provides TLC with a specification and one to models. The specification - written as a temporal formula (see section 2.1.4) - specifies the system; such as the Bakery mutual exclusion algorithm (Lamport, 1974). Conceptualized, the specification can be seen as the definition of the system's set of behaviors . A model on the other hand, declares the set of properties , that the system is expected to satisfy. In case of the Bakery algorithm, a user may wish to verify the safety property, that no two processes are in the critical section simultaneously. Also, the model declares additional input parameters, such as (system) constants and TLC runtime options. The parameters shall not concern us here.
With regards to checking safety properties, TLC consists of a generator procedure to create the state graph , which we called the transition system in section 2.1.
First, the procedure generates the specification's initial states . Afterwards, given a state and the specification's actions, TLC enumerates all possible successor- or next-states (see in section 2.1). Simplified, each successor state s is fed to the second procedure. The second procedure checks, if the state satisfies the model's safety properties . If a state is found to violate a property, a counterexample is constructed. The first procedure generates the state graph on-the-fly by running BFS.4 Consequently, it maintains two sets of states:
- The unseen set S to store newly generated, still unexplored states. A term synonymously used for S in the context of TLC is state queue.
- The seen set C to store explored states. TLC calls C the fingerprint set motivated by the fact that C stores state hashes rather than states (more on that later).
Contrary to regular BFS, TLC maintains a third data structure to construct a counterexample:
- A (state) forest of rooted in-trees to construct the shortest path from any state back to an initial state . The states in correspond to the roots in . The PlusCal pseudo-code in algorithm 1 shows a simplified variant of TLC's algorithm to check safety properties (full listing in section B.1). Readers, unfamiliar with TLA+ or PlusCal, are referred to the reference list in appendix A on page 117 for a brief introduction of the language constructs. First, TLC generates the initial states atomically and adds them to the set of unseen states . The init loop checks each initial state for a violation.
If the state does not violate the properties, it is added to C (algorithm 1 line 6 to line 13). The second loop executes BFS (algorithm 1 line 14 to line 30). The operation corresponds to the next state relation (see → in section 2.1). The check represents the procedure to verify the safety properties . TLC naïvely parallelizes BFS by concurrently executing the while loop scsr with multiple threads - called workers.
The global data structures , , are shared by all workers. Consequently, each data structure has to be guarded by locks to guarantee consistency. Sharing among all workers achieves optimal load-balancing. We call this mode of execution parallel TLC. TLC can also execute on a network of computers in what is called distributed mode [Kuppe, 2012]. Distributed TLC speeds up model checking.
TLC is implemented in and available on all operating systems supported by Java.
TLC runs on commodity hardware found in desktop computers, up to high-end servers equipped with hundreds of cores and terabytes of memory. It is capable of checking large-scale models, i.e. the maximum checkable size of a model is not bound to the available memory. Instead, TLC keeps the in-memory working set small:
- TLC swaps unexplored states in the unseen set S from memory to disk. The unseen set S has a fixed space requirement.
- TLC constantly puushes the forest to disk. Iff a violation is found, TLC reads the forest back to disk to construct the counterexample.
- The seen set - whenever it exceeds its allocated memory - extends to disk.
1 and 2 enable TLC to allocate the majority of memory to the seen set . When the seen set exceeds its allocated memory (3), TLC is said to run disk-based model checking. Once TLC switches to disk-based model checking, its performance, i.e. the number of states generated per unit of time, drops significantly. Still, disk-based model checking has its place. It makes the verification of state space tractable, for which the primary memory alone is insufficient, e.g. Newcombe [2014] gives an account where TLC ran for several weeks to check a state space of approximately states.
TLC supports the use of TLC module overwrites in TLA+ and PlusCal specifications. A TLC module overwrite is a static Java method which matches the signature of a TLA+ operator. With a TLC module overwrite in place, TLC delegates the evaluation of the corresponding TLA+ operator to the Java method. Generally, this is assumed to be faster. A TLC module overwrite is stateless and cannot access its context.
Additionally, TLC module overwrites make the Java library available to TLA+ users.
What's the difference between the behavior graph and state exploration graph?
The behavior graph is the cross product of the state graph and the tableau that represents the liveness property.
Trace Validation
This is a comment from Markus Kuppe from Github.
Trace Validation (TV) essentially adopts this approach by mapping recorded implementation states to TLA+ specification states. This method is practical as it derives implementation states directly from the execution of the implementation, avoiding the complexities of symbolic interpretation of the source code. However, TV is not exhaustive. It verifies that only a certain subset of all potential system executions aligns with the behaviors defined in the specification. Nevertheless, this is not necessarily a limitation if the chosen subset of system executions is sufficiently diverse. For example, in CCF, among other discrepancies, we were able to find two significant data-loss issues using TV with just about a dozen system executions.
It also allows you to use the specification to drive the testing of the implementation.
In CCF, this feature is still on our roadmap. However, manually translating TLA+ counterexamples (violations of the spec's correctness properties) into inputs for the implementation was straightforward.
Why Trace Validation is Useful
You can use it to check that the implementation is in sync with your spec, or even go as far as generating a complete spec from the code. See discussion here.
Depth-First Search
Depth-First Search for trace validation.
To run a DFS, use:
JVM_OPTIONS=-Dtlc2.tool.queue.IStateQueue=StateDeque
StateDequeue was added in Jan 2024.
Resources:
Liveness checks
if TLC is configured to check three temporal formulas A,B,C; TLC does not check if A, B or C are identical formulas. If TLC is set to check A, A, A (it will still create three OrderOfSolutions). It is up to the user to prevent this.
Standard Library
Community Modules
Debugger
TLA+ tools come with a debugger that allow you to debug your specifications. See it in action:
graphical and time-traveling debugging
You will need the SVG extension: https://marketplace.visualstudio.com/items?itemName=jock.svg.
{kind=link}
Coverage (draft)
The number of times each action was taken to construct a new state. Using this information, we can identify actions that are never taken and which might indicate an error in the specification.
How to read coverage?
// Determine if the mapping from the action's name/identifier/declaration to the
// action's definition is 1:1 or 1:N.
//
// Act == /\ x = 23
// /\ x' = 42
// vs
// Act == \/ /\ x = 23
// /\ x' = 42
// \/ /\ x = 123
// /\ x' = 4711
// or
// Act == (x = 23 /\ x' = 42) \/ (x = 123 /\ x' = 4711)
//
// For a 1:1 mapping this prints just the location of Act. For a 1:N mapping it
// prints the location of Act _and_ the location (in shortened form) of the actual
// disjunct.
// 1:1
return String.format("<%s %s>", this.action.getName(), declaration);
} else {
// 1:N
return String.format("<%s %s (%s %s %s %s)>",
At high level, it's defined as:
MP.printMessage(EC.TLC_COVERAGE_VALUE_COST,
new String[] { indentBegin(level, TLCGlobals.coverageIndent, getLocation().toString()),
String.valueOf(count), String.valueOf(cost) });
as an example:
<Next line 13, col 1 to line 13, col 4 of module Github845 (15 8 17 24)>: 0:2
0:2 at the end mean:
- number of distinct states discovered after taking this action
- total cost of this action.
if it only has a value, like this:
line 23, col 6 to line 23, col 40 of module M: 1536
that's the count.
for lines like these:
[junit] line 23, col 6 to line 23, col 40 of module M: 1536
[junit] |line 23, col 18 to line 23, col 40 of module M: 192:4608
[junit] ||line 23, col 19 to line 23, col 28 of module M: 192
[junit] ||line 23, col 33 to line 23, col 39 of module M: 192
the pipe prefix is for subcomponent of the action. In this case, line 23 is:
/\ active' \in [{23,42,56} -> BOOLEAN]
What is cost?
Cost is the number of operations performed to enumerate the elements of a set or sets, should enumeration be required to evaluate an expression
At top level action it usually points to the max of the cost of all children nodes I think?
Profiling a specification is similar to profiling implementation code: During model checking, the profiler collects evaluation metrics about the invocation of expressions, their costs, as well as action metrics. The number of invocations equals the number of times an expression has been evaluated by the model checker. Assuming an identical, fixed cost for all expressions allows to identify the biggest contributor to overall model checking time by looking at the number of invocations. This assumption however does not hold for expressions that require the model checker to explicitly enumerate data structures as part of their evaluation. For example, let S be a set of natural numbers from N to M such that N << M and \A s \in SUBSET S : s \subseteq S be a expression. This expression will clearly be a major contributor to model checking time even if its number of invocations is low. More concretely, its cost equals the number of operations required by the model checker to enumerate the powerset of S. Users can override such operators with more efficient variants. Specifically, TLC allows operators to be overridden with Java code which can often be evaluated orders of magnitudes faster.
Good to know:
Why isn't Next's coverage reported?
TLC does not evaluate Next but turns its two disjuncts into separate sub-actions internally.
Why isn't ASSUME's coverage reported?
-
Coverage statistics are not collected for ASSUME statements.
-
Coverage statistics are not reported for operators called (directly or indirectly) from top-level actions (with this patch I see that such expressions are only reported if they have 0 cost).
More references
- https://tla.msr-inria.inria.fr/tlatoolbox/doc/model/profiling.html
Generating stage graphs
TLC support the generation of a dot file that can be used to visualize the state space.
first generate dot file:
java -cp ./dist/tla2tools.jar tlc2.TLC -dump dot test.dot /home/fponzi/dev/tla+/Examples/specifications/glowingRaccoon/clean.tla
then visualize the graph:
- http://www.webgraphviz.com/
- From CLI:
dot -Tps filename.dot -o outfile.ps
If the state graph is large, you can try to visualize it using:
- https://cytoscape.org/index.html
- https://gephi.org/
If you use intellij, there is a plugin to visualize/edit .dot files in the ide.
From the TLA+ Toolbox:
if dot is not installed in the standard path, please adjust the dot path in the Toolbox's preferences (File > Preferences > TLA+ Preferences > PDF Viewer > Specify dot command). Afterwards check "Visualize state graph after completion of model checking" before you run model-checking on the "Advanced Options" page of the model editor (see attached screenshot). The Toolbox will then add a tab to the model editor showing the state graph once model checking has completed.
Note that the visualization is only useful for small state spaces. For larger ones, the dot rendering will timeout. In this case you can try to render the dot output file manually on the command line with a different dot settings, i.e. layout. The dot file is found in the model subdirectory of your specification.
Generating sequence diagrams
This is a tool for generating sequence diagrams from TLC state traces. It produces SVGs that look like:
 or like this PDF.
or like this PDF.
Link to the tool here.
TLA+ Web Explorer
Homepage and the source code is hosted on GitHub.
The current version of the tool utilizes the TLA+ tree-sitter grammar for parsing TLA+ specs and implements a TLA+ interpreter/executor on top of this in Javascript. This allows the tool to interpret specs natively in the browser, without relying on an external language server. The Javascript interpreter is likely much slower than TLC, but efficient model checking isn't currently a goal of the tool.
Watch the presentation:
Generating Animations of State Changes
Writing animation specifications is straightforward. There is a module that provides TLA+ definitions of SVG primitives. Below are a few examples. The first three are for TLC, and the other ones are for Will Schultz's TLA-web. Despite being for different systems, the definitions are quite similar.
- https://github.com/tlaplus/Examples/blob/master/specifications/ewd998/EWD998_anim.tla
- https://github.com/tlaplus/Examples/blob/master/specifications/ewd687a/EWD687a_anim.tla
- https://github.com/tlaplus/Examples/blob/master/specifications/ewd840/EWD840_anim.tla
- https://github.com/will62794/tla-web/blob/master/specs/EWD998.tla#L123-L201
- https://github.com/will62794/tla-web/blob/master/specs/AbstractRaft_anim.tla#L210-L280
The animations can be created in the Toolbox with:
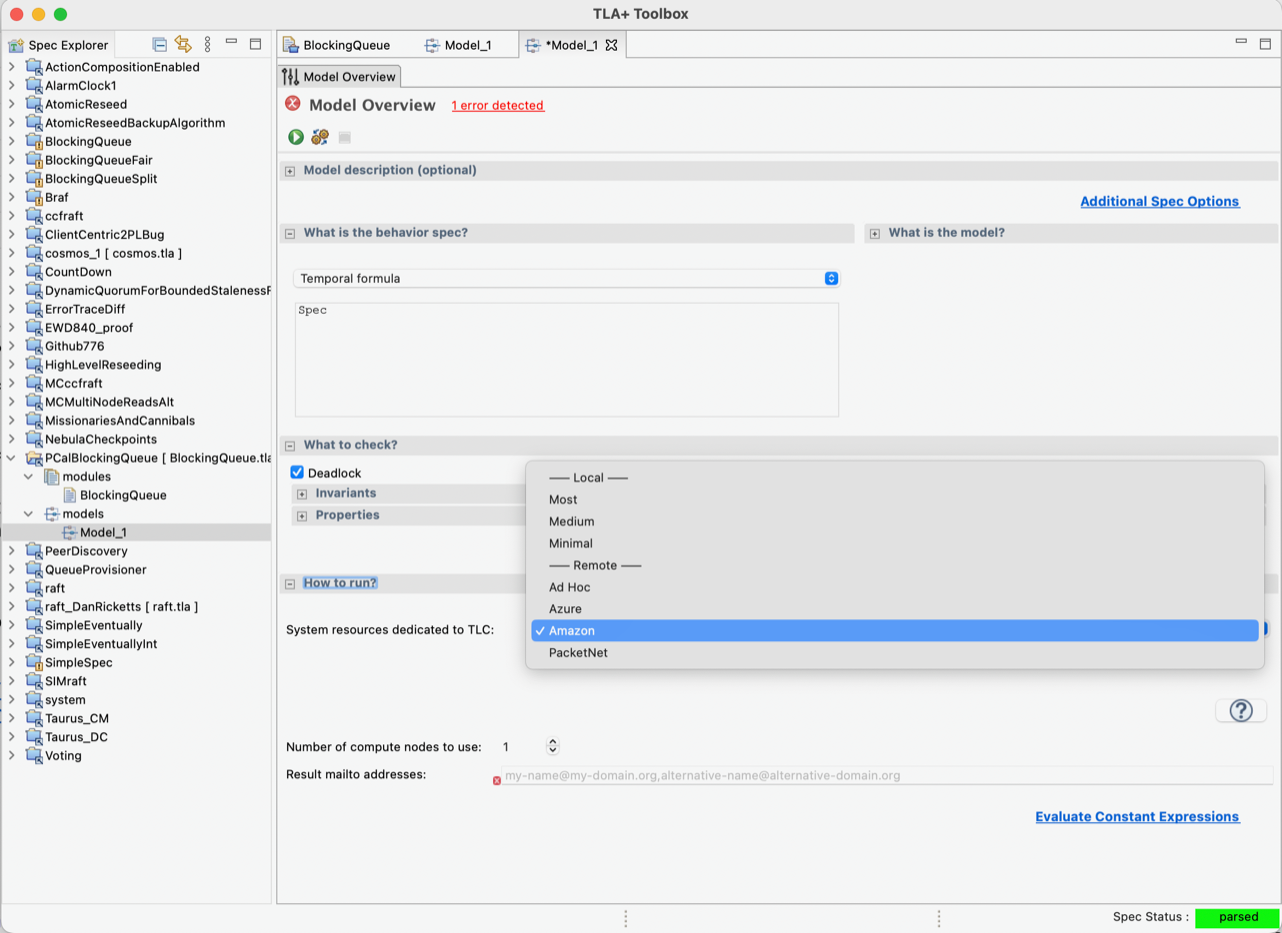
- Check model BlockingQueue.cfg
- Set
Animationas the trace expression in the Error-Trace console - Hit Explore and export/copy the resulting trace to clipboard
- Paste into http://localhost:10996/files/animator.html
Without the Toolbox, something similar to this:
- Check model BlockingQueue.cfg with
java -jar tla2tools.jar -deadlock -generateSpecTE BlockingQueue('-generateSpecTE' causes TLC to generate SpecTE.tla/.cfg) - State trace expression
Animation(BlockingQueueAnim.tla)in SpecTE.tla - Download https://github.com/tlaplus/CommunityModules/releases/download/20200107.1/CommunityModules-202001070430.jar
- Check SpecTE with
java -jar tla2tools.jar:CommunityModules-202001070430.jar tlc2.TLC SpecTE - Copy trace into http://localhost:10996/files/animator.html (minor format changes needed)
CI for your specifications
Generating GO from pluscal specs
PGo is a source to source compiler that translates Modular PlusCal specifications (which use a superset of PlusCal) into Go programs.
- Homepage: https://distcompiler.github.io/
- Repo: https://github.com/DistCompiler/pgo
Watch the talk to the TLA+ 2019 conf:
You can also read the related paper: Compiling Distributed System Models with PGo
AI Linter
TLA+ does not come with a traditional linter or formatter. The TLA+ AI Linter is a GenAI script that uses LLMs to lint TLA+ files.
Find more info on: https://microsoft.github.io/genaiscript/case-studies/tla-ai-linter/
Generating tests from models
You can use modelator: https://github.com/informalsystems/modelator
It can be installed through pip (python's package manager):
pip install modelator
Limitations
TLA+ codebase
The tlaplus codebase is very complex. There are over 600k lines of code, in over 2000 files, written over 20+ years. And yet as the best distributed systems modelling tool on the market today, maintaining and improving it is critical.
TLA+ should be regarded as a piece of mission critical software, like a cryptography library. This means that it cannot accept any kind of change that could potentially break it. Especially because being open source software means that somebody will also need to spend time fixing it.
This chapter is meant to orient new programmers that want to navigate the codebase and start contributing, as well as reorient existing ones.
Contributing
TL;DR: engage maintainers early & often, be surgical in your changes, and write lots of tests.
We welcome contributions to this open source project! Before beginning work, please take some time to familiarize yourself with our development processes and expectations. The TLA⁺ tools are used to validate safety-critical systems, so maintaining quality is paramount. The existing code can also be quite complicated to modify and it is difficult to review changes effectively. So, there are several practices that are necessary for having a good contribution experience. The last thing anybody wants is for you to feel as though you have wasted your time! If you open a massive pull request (PR) out of nowhere it is very unlikely to be merged. Follow this guide to ensure your effort is put to the best possible use.
Always remember that we are all volunteers here. Be kind to everybody! You can review our Code of Conduct here.
The Contribution Process & Style
The most important step is to engage with existing developers & maintainers before beginning work. The best way to do this is to comment on an issue you want to fix, or open a new issue if a suitable candidate does not exist. It is also very helpful to join the monthly online community meeting to introduce yourself and speak with people directly. The development team will help you better understand the scope & difficulty of the proposed changes, along with what parts of the codebase they'll touch and what additional tests are required to safely merge them. Building & maintaining consensus around these aspects will ensure a smooth review & merge process.
To begin work on your change, fork this repository then create an appropriately-named branch to track your work. You will eventually submit a PR between your feature branch and the master branch of this repository, at which point developers & maintainers will review your changes. After integrating this feedback your PR will then hopefully be merged.
When creating and submitting your changes, closely follow these guidelines:
- Be surgical: What is the smallest diff you can make that still accomplishes your goal? Avoid the urge to fix unrelated stylistic issues in a file you are changing.
- Write tests first: If you're changing a specific part of the codebase, first ensure it has good test coverage; if it does, write a few more tests yourself anyway! Writing tests is a great way to learn how the code functions. If possible, submit your tests in a separate PR so their benefits can be realized immediately. We don't fully subscribe to Test-Driven Development (TDD) but having good existing test coverage of a changed area is a prerequisite to changes being merged.
- Split up your changes: If parts of your changes provide some benefit by themselves - like additional tests - split them into a separate PR. It is preferable to have several small PRs merged quickly than one large PR that takes longer to review.
- Craft your commits well: This can require advanced git knowledge (see DEVELOPING.md). Treat your commits as forms of communication, not a way to bludgeon the codebase into shape. You don't need to check this, but ideally the build & tests should pass on every commit. This means you will often be amending commits as you work instead of adding new ones.
When you open a PR against this repo, the continuous integration (CI) checks will run. These ensure your changes do not break the build & tests. While you can run most of these checks locally, if you'd like to run the CI at any time you can open a PR between your feature branch and the master branch of your own fork of this repo.
Contribution Possibilities
These tools have a large number existing issues to fix, which you can see on the repo's issues tab. In particular, consider looking at issues tagged with "help wanted". For new developers, there are issues tagged "good first issue".
For new features, there are a number of substantial improvements we'd like to see implemented. If you have an idea for a new feature, open an issue in this repository to start a discussion. For more fundamental proposals that involve changes to the TLA⁺ language itself, you can open a RFC. Often it will be necessary to build community support for your idea; for this you can use the mailing list and especially the monthly online community meeting. Expressions of goodwill like volunteering labor to review pending PRs is also appreciated!
Non-code contributions are also welcome! There is ample work available in expanding developer documentation (like this very document) or user-facing TLA⁺ documentation. We also collect quality metrics, and the reports indicate several low-hanging fruits to pick.
Getting Started
Take the time to set up your local development environment. See DEVELOPING.md for details. Good luck, and have fun!
Setting up the development environment
For eclipse, you can follow directions here: https://github.com/tlaplus/tlaplus/tree/master/general/ide
For intellij, if you plan to contribute to tlc, it's fine to just open the related package from there.
Debugging and rootcausing issues
Start from the MRE
Minimum Reproducible Example. Often, if you can get one half of your problem is solved. This is why is so important to provide one when creating issues. The smaller the state graph needed to reproduce the issue, the better.
Write a regression test
Write a test, and make sure it fails. After your fix is applied, the test should start passing again. When writing the regression test, make sure to think what could happen if you have multiple workers involved. Do you need to test that as well?
Generate the state graph
See generating state graphs page. State graphs can help visualize what's going on.
Run your spec with assertion turned on.
TLC has a -ea option that will enable some assertions in the code. It might be able to help catching some edge case hit by your code.
Run with debugging logs
I don't find these particular helpful, but it's worth trying. Run tlc with -debug on and you will get additional debug logs in output.
Attaching a debugger
To the final jar:
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=*:5005 -jar ./dist/tla2tools.jar /tmp/genereto/Github710a.tla
Eliminate randomness
To enanche reproducibility. Use -fp and -seed.
java -jar ./dist/tla2tools.jar -lncheck final -fpmem 0.65 -fp 120 -seed -8286054000752913025 -workers 10 /tmp/genereto/Github710a.tla
CustomBuild parameters
customBuild.xml supports different parameters to tune the tests. These can also be combined.
Running a test with a debugger
-Dtest.suspend=y will suspend the execution and give you time to hook up a debugger before running a test.
ant -f customBuild.xml compile-test test-set -Dtest.suspend=y -Dtest.testcases="tlc2/tool/InliningTest*"
Specify number of threads
By default uses all your cores. You can specify a custom amount using -Dthreads=4:
ant -f customBuild.xml test -Dthreads=4
Halt tests when a failure is found
By default the test target will run all the test and report success or failure only at the end. It can be convinient to just stop execution as soon as an error is found, with-Dtest.halt=true.
ant -f customBuild.xml test -Dtest.halt=true
CI/CD overview
The CI/CD is currently handled by Github Actions.
The tests are run as part of every PR and for every merge to main. The codebase is built against both Mac and Linux.
Pluscal (+cal)
To learn more about pluscal, the language and how the generation process works check this out: https://github.com/tlaplus/tlaplus/blob/ab14a33e39c78e4c88e81b664b9a8c916b943cab/tlatools/org.lamport.tlatools/src/pcal/PlusCal.tla.
Changing the pluscal translator
The pluscal translator can be thought as the pluscal "compiler" which takes as input pluscal code and produces tla+ in output.
For this reason, the pluscal translator is versioned. Any change to the pluscal traslator that could result in a different output, will required a verison bump.
See as an example: https://github.com/tlaplus/tlaplus/pull/978/files
Codebase Architecture Walkthrough
Modules
- pcal: Converts the pcal language into TLA+ that can by run by TLC2.
- tla2tex: "Pretty Prints" TLA+ code into LaTex. This LaTex can then be used for publishing.
- tla2sany: Contains the AST and parsing logic for the TLA+ language. The AST classes generated from parsing are used by TLC2.
- tlc2: The model checker to validate the AST generated by tla2sany. This is the largest and most complex part of the codebase by far.
The Standard Flow
This is a generalized mplified description of how this code is normally used, and the involved components. More detail will be given on some of these components in the following sections.
- (Optional) PCal code translated into TLA+ code. pcal.trans::main
- TLC2 Model Checker run from standard entrypoint tlc2.TLC::main on that code and associated .cfg file
- TLC2 class created, arguments parsed, and processing started. tlc2.TLC::TLC, TLC::handleParameters, TLC::process
- The spec is parsed and stored in Tool. This occurs in the Tool constructor.
- A SpecObj is created with file information about the spec
- A SpecProcessor is created with that SpecObj
- At the start of processing the spec, SpecProcessor calls SANY::frontEndMain that parses the spec into an AST
- The SpecProcessor performs a number of extraction and analysis operations on the AST.
Note: These are called in a precise order in the Tool constructor. Modifying this is highly error prone, though the tests will fail reliably if there is an issue.
- The Tool takes the results of all these operations and assigns them to final variables. The Tool is now the only source of truth for specification information, and is immutable.
Note: This is a critical separation of concerns, to separate the complex job of parsing and resolving the spec, from the job of analyzing it. The tool is the only object that spans both.
- The following are selected and initialized
- The model checker or simulator. This class performs a certain type of analysis on the spec.
- ModelChecker: Standard Breadth-First checking of entire state space
- FPSet: Contains the fingerprints of all explored states.
- StateQueue: Contains new states to explore.
- DFIDModelChecker: Depth first checking of entire state space, to a pre-specified level of depth.
- Simulator: Randomized exploration and checking of the state space.
- ModelChecker: Standard Breadth-First checking of entire state space
- The model checker or simulator. This class performs a certain type of analysis on the spec.
- The analysis is performed
- Workers are run per configuration to allow multi-threaded analysis
- ModelChecker: Worker
- DFIDModelChecker: DFIDWorker
- Simulator: SimulationWorker
- Each checker performs analysis differently, but generally the analysis consists of generating new states from existing states, and checking those new states
- Workers are run per configuration to allow multi-threaded analysis
- The result is returned to the user
Model Checker Analysis
- The StateQueue is seeded with the initial states
- Workers take states of the StateQueue. From there they generate next potential states. They check that the fingerprint of the state is not already in the FPSet (such that analysis is not duplicated). They then check that state for safety properties, and add it to both the FPSet and the StateQueue.'
- Periodically the analysis pauses. If configured to create a checkpoint, a checkpoint is created. If configured to check temporal properties, the Liveness Checking workflow (described below) is performed by calling LiveChecker::check. Once done the analysis continues.
- When the StateQueue is empty or an error is detected, the analysis is over.
Performance Note: The vast majority of CPU cycles are spent either calculating fingerprints or storing fingerprints in the FPSet.
Depth-First Checker Analysis
- Data structure initialized with InitStates
- The analysis occurs by setting a temporary max depth that increases to the configured maximum depth
- Worker retrieves unexplored initial state, removing it from the set of init states
- Worker explores the state space depth first up to the temporary max depth, storing all seen states in the FPIntSet
- Periodically the analysis pauses. If configured to create a checkpoint, a checkpoint is created. If configured to check temporal properties, the Liveness Checking workflow (described below) is performed by calling LiveCheck::check. Once done the analysis continues.
- Once there are no more levels to explore, or an error is detected, the analysis is over
Simulator Analysis
- Initial states calculated and checked for validity
- Each SimulationWorker retrieves a random initial state
- Next states are randomly generated and checked, up to a specified depth. Each one of these runs is a trace.
- If liveness checking is enabled, check the trace with LiveChecker::checkTrace
- Once the specified number of traces have been run, or an error is detected, the analysis is over
Liveness Checking
Liveness checking is what allows checking of temporal properties.
Liveness checking is initiated by calling: LiveCheck::check or checkTrace.
Every time this occurs it creates new LiveWorker(s) to perform the analysis.
Note: Unlike standard model checking, Liveness Checking by default is not guaranteed to produce the shortest trace that violates the properties. There is a AddAndCheckLiveCheck that extends LiveCheck that attempts to do this, at the cost of significant performance. It is selected in the constructor of AbstractChecker.
States and Fingerprints
States are a fundamental part of TLC. They represent a set of variable values, that entirely determine the state of the system. States are generated and checked as part of the TLC2 analysis process. The base class for this is TLCState.
Fingerprints are hashes taken of these states using the FP64 hash. Fingerprints are a 64bit hash representing the state. This is significantly smaller than storing the state itself, and yet collisions are very unlikely (though if they did occur, part of the statespace would not be explored). The fingerprinting process is initiated from TLCState::generateFingerPrint.
There are two primary implementations of state that are very similar:
- TLCStateMut: Higher performance, records less information
- TLCStateMutExt: Lower performance, records more information
Effectively, functions that are no-ops in TLCStateMut, persistently store that information in TLCStateMutExt. This information can include the name of the generating action, and is often needed for testing / debugging purposes.
The implementation to use is selected in the constructor of Tool, by setting a reference Empty state for the analysis.
High Performance Datastructures
The ModelChecker performs a breadth-first search. In a standard BFS algorithm, there are two main datastructures: a queue of items of explore next, and a set of the nodes already explored. Because of the sheer size of the state space for the ModelChecker, specialized versions of these datastructures are used.
Note: These data-structures are a large focus of the profiling / testing work, because both performance and correctness are key for the ModelChecker to explore the full state space.
Fingerprint Sets (FPSets)
FPSets are sets with two main operations
- put fingerprint
- determine if fingerprint in set
Located in tlc2.tool.fp. All but FPIntSet extend FPSet. FPIntSet is used specifically for depth-first-search and is not discussed here.
In practice the performance and size of the FPSet determine the extent of analysis possible. The OffHeapDiskFPSet is in practice the most powerful of the FPSets, efficiently spanning the operations across off-heap memory and the disk. There are also memory only FPSets that may be preferable for smaller state spaces.
StateQueue
Located in tlc2.tool.queue, with all implementations extending StateQueue.
The default implementation is DiskStateQueue. Because of the size of the queue, storing it in memory may not be an option.
Symmetry Sets
A discussion of Symmetry Sets can be found here.
They are implemented in the TLCState::generateFingerPrint function by calculated all permutations of a particular state (for all symmetry set model values), and returning the smallest fingerprint. Therefore all permutations would have a same fingerprint, and so only the first example generated would be explored.
Note: The order dependant nature of the fingerprint means that when using symmetry sets, the majority of the cpu cycles are spent "normalizing" the data structures such that the order the fingerprint gets assembled in are consistent. An order independent fingerprint hash would remove this performance hit, however would significantly increase the likelihood of collisions unless the hash algorithm itself was upgraded.
Debugger
The AttachingDebugger is the main debugger. It works in conjunction with the DebugTool to allow a user to step through a TLC execution.
Note: Using the debugger will keep the process alive indefinitely due to the listener. The eclipse network listener is not interruptable, so thread interruption behavior will not work. It relies on process exit.
Coverage
The coverage functionality determines what statements in the TLA+ spec have been used. Located in tlc2.tool.coverage
Unique Strings
String comparison can be a relatively expensive operation compared to primitive comparison. There are lots of string comparisons required in the code, but with a relatively limited set of strings.UniqueString maps each string to a monotonically increasing integer. Then comparisons are reduced to the much cheaper integer comparisons. This is used throughout the codebase.
Architecture of the TLA+ Toolbox (IDE)
This paper by Kuppe et al presents the technical architecture of the toolbox in this paper: https://arxiv.org/pdf/1912.10633
Codebase Idiosyncrasies
As a 20 year old code base, one can expect idiosyncrasies that do not match current best practice. There are also inherent idiosyncrasies to any language interpreter. Maintaining functionality and performance is the most important concern. However whenever these idiosyncrasies can be removed without compromising those, they should be.
Dynamic Class Loading
This project makes extensive use of Classloaders. This can make it slightly more difficult to debug / statically analyze. Critical usecases are called out here.
Operators / Modules
The ClassLoader is used to load both standard modules and user created modules. The standard modules can be found here:
The SimpleFilenameToStream class is used to read in this information, and contains the logic about standard module directories. It is where the ClassLoader is used. TLAClass is also used for a similar purpose, used to loader certain built in classes.
The classpath of the created jar explicitly includes the CommunityModules such that they can be loaded if available.
CommunityModules-deps.jar CommunityModules.jar
Users can also create custom operators and modules and load them similarly.
The methods are invoked with:
mh.invoke
mh.invokeExplict
And this is done in a small number of locations: MethodValue CallableValue PriorityEvaluatingValue
FPSet Selection
FPSets are dynamically selected using a system property and loaded with a ClassLoader in the FPSetFactory.
Misc
- TLCWorker: Used to load certain sun class dependencies if available.
- BlockSelectorFactory: Used to modularity load a custom BlockSelectorFactory.
- TLCRuntime: Used to get processId
Notable Mutable Static State
The original codebase was written with the intention of being run from the command line only.
There is a significant amount of static state. While much has been removed
Testing Brittleness
The end to end test suite is a very powerful tool of the project. It does have a reliance on the execution occurring in a very precise order. There are certain race conditions in the codebase that can cause some inconsistency in execution statistics, even while providing correct behavior. This can cause some tests to fail. Additionally, there are some race condition bugs. Additonally. It is not always easy to determine which case it falls into, and so categorizing / fixing these test cases should lead either codebase or test suite improvements.
Independently Run Tests
In order to allow tests to be independently run, we add one of the following tags depending on whether it is a standard test or a TTraceTest
@Category(IndependentlyRunTest.class)
@Category(IndependentlyRunTTraceTest.class)
In general, these should be used sparingly, and instead if a test fails when run with others, the root cause should be discovered and fixed.
Unique String ordering reliance
As mentioned above, unique strings replace strings with a consistent integer token for faster comparison. That token is monotonically increasing from when the unique string is generated. When comparing unique strings, it compares the tokens, meaning the ordering of the UniqueString based collection is dependant on the ordering of the creation of strings. This can break tests that hardcode the ordering of the result output when they are not run in isolation. This isn't necessarily a fundamental problem with the system, as the output is consistent based on TLA+ semantics which does not differ based on order.
The tests that fail for this reason are marked as independent tests, but grouped under
<id>unique-string-conflicts</id>
in pom.xml. Their reason for failure is known.
Debugger Tests
The AttachedDebugger currently only terminates on process exit. For that reason, all debugger tests are marked with the annotation below, and run as independent processes.
@Category(DebuggerTest.class)
Primitive Versions of Standard Data Structures
The standard collections in the Java standard library store only objects. Some custom collections are required that can store and/or be indexed by primitives. These are needed for performance reasons.
Note: There may be more not listed here, but ideally they should be added.
Unchecked Casting
As a language interpreter, there are a number of Abstract Syntax Tree node types. In many cases, functions use unchecked casts to resolve these node types, often after using if statements to check the nodes type.
To find all the classes / functions that do this, search for:
@SuppressWarnings("unchecked")
Whenever possible unchecked casts should be replaced with pattern matching instanceof. This generally is a good fit for most of the code in the codebase.
Dead Code
This project was initiated prior to "good" version control. Therefore modern anti-patterns such as commenting out code and leaving unused methods, classes, etc have propagated. Significant amounts of dead code have been removed. Because of the use of reflection / classloaders, static analysis tools may indicate certain items are unused when they are actually depended on. Dead code removal needs to be done in conjunction with testing and exploration.
Acceptable Dead Code
A certain amount of dead code may have explanatory purpose.
- Standard methods implemented on data structures: ideally they should be tested, but some are not.
- Semantic variables / properties that are set appropriately but unread: They serve as a form of comment. Misleading examples of these should be removed.
- Small amounts of inline, commented out code that changes particular functionality or configures the codebase.
- Tested classes that implement used interfaces, where the class is not currently used: These still have explanatory purpose.
Any of this code should be removed when it loses relevance or accuracy.
Dead Code to be Removed
- Commented out methods
- Orphan classes
- Large amounts of inline commented out code without sufficient explanatory power
- Unused, untested, non-standard methods: Version control can be used if they are needed, but they add confusion and may be broken
Inconsistent Formatting
The formatting of certain classes is inconsistent and doesn't work well with modern IDEs. Ideally an autoformatter would be run on the codebase to fix this. However, as this is a fork of the primary codebase, it is left unrun to allow better diffs with the upstream repo.
JMX / Eclipse Integrations
This project was initially developed as an Eclipse project, so it includes a number of Eclipse libraries and technologies. Most of them integrate rather seamlessly as dependencies, while enabling specialized diagnostic functionality for Eclipse.
The project has AspectJ source that can be compiled in for additional diagnostics. It is also required for Long Tests to pass. The sources are located in src-aspectj.
Additionally this project uses Java Management Extensions for diagnostic purposes. They are always used an can be a source of memory leaks.
Java Pathfinder
There are java pathfinder tests in the project. Sources are located in test-verify. Additional information on these tests can be found in test-verify/README.
Wishlist: List of projects to extend/improve TLA+, TLC, TLAPS or the Toolbox
Please also consult the issues tracker if you want to get started with contributing to TLA+. The items listed here likely fall in the range of man-months.
TLC model checker
(In Progress) Concurrent search for strongly connected components (difficulty: high) (skills: Java, TLA+)
One part of TLC's procedure to check liveness properties, is to find the liveness graph's strongly connected components (SCC). TLC's implementation uses Tarjan's canonical solution to this problem. Tarjan's algorithm is a sequential algorithm that runs in linear time. While the time complexity is acceptable, its sequential nature causes TLC's liveness checking not to scale. Recently, concurrent variants of the algorithm have been proposed and studied in the scope of other model checkers (Multi-Core On-The-Fly SCC Decomposition & Concurrent On-the-Fly SCC Detection for Automata-Based Model Checking with Fairness Assumption). This work will require writing a TLA+ specification and ideally a formal proof of the algorithm's correctness.
Liveness checking under symmetry (difficulty: high) (skills: Java, TLA+)
Symmetry reduction techniques can significantly reduce the size of the state graph generated and checked by TLC. For safety checking, symmetry reduction is well studied and has long been implemented in TLC. TLC's liveness checking procedure however, can fail to find property violations if symmetry is declared. Yet, there is no reason why symmetry reduction cannot be applied to liveness checking. This work will require writing a TLA+ specification and ideally a formal proof of the algorithm's correctness.
TLC error reporting 2.0 (difficulty: moderate) (skills: Java)
TLC can only check a subset of TLA+ specifications. This subset is left implicit and a user might use language constructs and/or models that cause TLC to fail. Not infrequently, it comes up with the very helpful report “null”. To lower to barrier to learning TLA+, TLC error reporting has to better guide a user.
Improved runtime API for TLC (difficulty: moderate) (skills: Java)
The TLC process can be long running. It possibly runs for days, weeks or months. Today, the Toolbox interfaces with the TLC process via the command line. The Toolbox parses TLC's output and visualizes it in its UI. This is a brittle and read-only interface. Instead, communication should be done via a bidirectional network API such as RMI, JMX or REST. A network interface would even allow users to inspect and control remotely running TLC instances, e.g. those running in the cloud started through cloud-based distributed TLC. A network interface is likely to require some sort of persistence mechanism to store model runs. Persistence of model runs is trivially possible with today's text based solution. Desirable user stories are:
- Pause/Resume TLC
- Reduce/Increase number workers
- Trigger checkpoints and gracefully terminate
- Trigger liveness checking
- Inspection hatch to see states currently being generated
- Metrics overall and for fingerprint set, state queue, trace
- ...
TLAPS
Automatic expansion of operator definitions (difficulty: moderate) (skills: OCaml)
TLAPS currently relies on the user to indicate which operator definitions should be expanded before calling the back-end provers. Forgetting to expand an operator may make an obligation unprovable, expanding too many operators may result in a search space too big for the back-end to handle. The objective of this work would be to automatically detect which definitions have to be expanded, based on iterative deepening and possibly heuristics on the occurrences of operators in the context. The method could return the list of expanded operators so that it can be inserted in the proof, eschewing the need for repeating the search when the proof is rerun. Doing so requires modifying the proof manager but not the individual back-end interfaces.
SMT support for reasoning about regular expressions (difficulty: moderate to high) (skills: OCaml, SMT, TLA+)
Reasoning about TLA+ sequences currently mainly relies on the lemmas provided in the module SequenceTheorems and therefore comes with very little automation. Certain SMT solvers including Z3 and CVC4 include support for reasoning about strings and regular expressions. Integrating these capabilities in TLAPS would be useful, for example when reasoning about the contents of message channels in distributed algorithms. Doing so will require extending the SMT backend of TLAPS, including its underlying type checker for recognizing regular expressions, represented using custom TLA+ operators.
Generate counter-examples for invalid proof obligations (difficulty: moderate to high) (skills: OCaml, TLA+)
Most conjectures that users attempt to prove during proof development are in fact not valid. For example, hypotheses needed to prove a step are not provided to the prover, the invariant may not be strong enough etc. When this is the case, the back-end provers time out but do not provide any useful information to the user. The objective of this work is to connect a model generator such as Nunchaku to TLAPS that could provide an explanation to the user why the proof obligation is not valid. The main difficulty will be defining a translation from a useful sublanguage of TLA+ set-theoretic expressions to the input language of Nunchaku, which resembles a functional programming language.
Warning about unexpanded definitions (difficulty: moderate) (skills: OCaml, TLA+)
A common reason for a proof not to succeed is the failure to tell the prover to expand a definition that needs to be expanded (see section 6.1 of Proving Safety Properties for an example). In some cases, simple heuristics could indicate that a definition needs to be expanded--for example, if a goal contains a symbol that does not appear in any formula being used to prove it. The objective is to find and implement such heuristics in a command that the user can invoke to suggest what definitions may need to be expanded. We believe that this would be an easy way to save users a lot of--especially beginning users.
TLA Toolbox
Port Toolbox to e4 (difficulty: easy) (skills: Java, Eclipse)
e4 represents the newest programming model for Eclipse RCP applications. e4 provides higher flexibility while simultaneously reducing boilerplate code. The TLA Toolbox has been implemented on top of Eclipse RCP 3.x and thus is more complex than it has to.
Add support for Google Compute to Cloud TLC (difficulty: easy) (skills: jclouds, Linux)
The Toolbox can launch Azure and Amazon EC2 instances to run model checking in the cloud. The Toolbox interfaces with clouds via the jclouds toolkit. jclouds has support for Google Compute, but https://github.com/tlaplus/tlaplus/blob/master/org.lamport.tla.toolbox.jclouds/src/org/lamport/tla/toolbox/jcloud/CloudDistributedTLCJob.java has to be enhanced to support Google Compute.
Add support for x1 instances to jclouds (difficulty: easy) (skills: jclouds)
We raised an enhancement request for the jclouds toolkit to add support for Amazon's largest compute instances (x1e.32xlarge, x1.32xlarge, x1.16xlarge).
Finish Unicode support (difficulty: easy) (skills: Eclipse, SANY)
A few outstanding issues prevent the integration of the Unicode support into the Toolbox. In addition to the open issues, adding unit tests would be welcomed. A nightly/ci Jenkins build is available.
TLA+ Tools
Pretty Print to HTML (difficulty: easy) (skills: Java, HTML)
TLA+ has a great pretty-printer to TeX (tla2tex), but HTML is becoming a de-facto document standard, especially for content shared online. HTML also has other advantages, such as the ability to automatically add hyperlinks from symbols to their definitions, and allow for collapsing and expanding proofs. The existing tla2tex code already contains most of the necessary parsing and typesetting pre-processing (like alignment), and could serve as a basis for an HTML pretty-printer. A prototype already exists.
Documentation and Code Quality
The TLA+ source code was written by multiple people over many years, so it has cosmetic problems that are distracting to new contributors. In general, we are not interested in cosmetic or stylistic improvements unless they also fix a concrete issue. Large refactors carry a big risk of introducing new defects, and we have rejected well-intentioned refactors in the past because they are too large or risky to review.
However, we are happy to accept small, easy-to-review changes that incrementally improve the TLA+ toolbox and tools. Below are a few meaningful ways to improve TLA+'s documentation and code quality.
Improve Internal Documentation (difficulty: easy) (skills: technical writing)
The TLA+ internal documentation for developers is limited. Improving this documentation would make it much easier for new contributors to get started.
Improve Test Coverage (difficulty: moderate) (skills: Java)
While the TLA+ tools have good test coverage, we would much prefer them to have great test coverage. This is a low-risk activity that any developer can help with.
Remove Uses of Global Mutable Variables (difficulty: high) (skills: Java) (low priority)
TLC cannot be easily used as a library in other projects because it makes extensive use of global mutable variables. This is not a problem for the normal use case; TLC has always been intended to run as an isolated process, not as a library. Using a separate process is a deliberate choice and a strength: the operating system provides isolation in case TLC runs out of memory and crashes. However, there would be real benefits to allowing TLC to be used as a library, e.g. reducing test suite execution time.
Fixing the existing uses of global variables must be undertaken carefully and incrementally. Previous efforts to do it have resulted in subtle soundness and completeness bugs.
Replace Custom Data Structures with Standard Java Collections (difficulty: moderate) (skills: Java) (low priority)
The TLA+ tools have handwritten implementations of many now-standard collection classes, such as tla2sany.utilities.Vector and tlc2.util.Vect, which duplicate the functionality of java.util.ArrayList. Replacing the handwritten ones with the standard types would have multiple benefits, including reducing our maintenance burden, reducing the size of the compiled tools JAR, and eliminating latent bugs. Note however that there are subtle differences between the handwritten implementations and the standard ones that must be accounted for.
Testing
test-dist:
Executes accompanying unit tests on jar file
ant -f customBuild.xml clean compile compile-test test-dist
To speedup, you can modify customBuild.xml and modify junit line inside of test-dist:
<junit printsummary="yes" haltonfailure="${test.halt}" haltonerror="${test.halt}" forkmode="perTest" fork="yes">
to use more threads: threads="8"
<junit printsummary="yes" haltonfailure="${test.halt}" haltonerror="${test.halt}" forkmode="perTest" fork="yes" threads="8">
Java Path Finder
Java Path Finder is a project developed by Nasa for model checking Java bytecode. See https://github.com/javapathfinder/jpf-core.
JPF is used to test some of the datastructures of tlatools. These tests can be invoked by using:
ant -f customBuild.xml compile compile-test test-verify
Resources
- Temporal Verification of Reactive Systems: Safety by Zohar Manna, Amir Pnueli. Section 5.5 "Particle Tableaux" is useful to understand the use of Tableaux for liveness verification in tlc codebase.
Glossary
- Stuttering (steps): steps in which the state of the system does not change.
TLA+ Community: what to do when you're stuck
- There is a very active google group: https://groups.google.com/forum/#!forum/tlaplus
- The TLA+ subreddit is also quite active: https://www.reddit.com/r/tlaplus/
- You can ask questions also on stackoverflow: https://stackoverflow.com/questions/tagged/tla%2b
- twitter: https://twitter.com/tlaplus